
”flink 流批一体化“ 的搜索结果
Spark Streaming是把流转化成一个个小的批来处理,Flink是把批当作一种有界的流。 1、Storm是第一代流处理框架,数据吞吐量和延迟上表现不尽人意,而且在数据准确性方面也存在不足。 2、Spark Streaming是第二代流...


flink流批一体存储
Flink 1.14流批一体新特性
标签: 大数据



上海数⽲信息科技有限公司⼤数据架构师杨涵冰,在 Flink Forward Asia 2022 流批一体专场的分享。
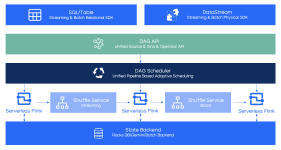
在Apache Flink的支持下,整个节日期间,GMV数值将稳定地实时显示在我们的大屏幕中。此外,在今年的活动中,基于Flink的阿里巴巴实时计算平台成功通过了年度测试。 除GMV仪表板外,Flink还为许多其他关键服务提供了...


Apache Flink 在诞生之初就确立了使用同一个引擎支持多种计算形态的目标,包括流计算,批处理和机器...本演讲将分享 Blink 针对流批一体化的场景做了哪些优化,在支持实际业务上碰到了哪些问题,我们又是怎么解决的。
Flink是一个优秀的流式处理引擎,不仅拥有完善的流式处理解决方案,而且将批处理视为有界流,完美实现了流批处理一体化。 Flink能干啥 流式分析 Flink可持续不断得处理事件流,并明确支持一下三种时间语义: ...
自 Google Dataflow 模型被提出以来,流批一体就成为...作为 Dataflow 模型的最早采用者之一,Apache Flink 在流批一体特性的完成度上在开源项目中是十分领先的。本文将基于社区资料和笔者的经验,介绍 Flink 目前(1
env.fromElements(可变参数)env.fromCollection(各种集合)env.generateSequence(开始,结束)env.fromSequence(开始,结束SourceFunction:非并行的随机数据源(并行度为1)RichSourceFunction:丰富的非并行的随机数据...
作者 | 蔡芳芳采访嘉宾 | 王峰、杨克特、黄晓锋流批一体已经从理论走向实践,并在 2020 年迎来落地元年。 短短 5 年,Apache Flink(下称 Flink)从一个突然出现在...


Shopee 研发专家李明昆,在 Flink Forward Asia 2022 流批一体专场的分享。
数据仓库是一个集成的(Integrated),面向主题的(Subject Oriented),随时间变化的(Time-Variant),不可修改的(Nonvolatile)数据集合,用于支持管理决策。这是数据仓库之父 Bill Inmon 在 1990 年提出的...
数字化经济革命的浪潮正在颠覆性地改变着人类的工作方式和生活方式,数字化经济在全球经济增长中扮演着越来越重要的角色,以互联网、云计算、大数据、物联网、人工智能为代表的数字技术近几年发展迅猛,数字技术与...


阿里巴巴开发工程师罗宇侠、阿里巴巴开发工程师方盛凯,在 Flink Forward Asia 2022 流批一体专场的分享。
精确一次语义:Flink的Checkpoint和故障恢复能力保证了任务在故障发生前后的应用状态一致性,为某些特定的存储支持了事务型输出的功能,即使在发生故障的情况下,也能够保证精确一次的输出。无论是来自 Web 服务器的...
基于Flink构建流批一体的实时数仓是目前数据仓库领域比较火的实践方案。随着Flink的不断迭代,其提供的一系列技术特性使得用户构建流批一体的应用变得越来越方便。本文将以Flink1.12为例,一一介绍这些特性的基本...
身为大数据工程师,你还在苦学Spark、Hadoop、Storm,却还没搞过Flink?醒醒吧!刚过去的2020双11,阿里在Flink实时计算技术的驱动下全程保持了“如丝般顺滑”,基于F...
推荐文章
- Java基础 高频面试题,2024年最新java多并发面试题-程序员宅基地
- vue视频播放插件vue-video-player的具体使用方法-程序员宅基地
- Element-UI 项目中 Pagination 分页如何使用 ???_element ui中pagination分页怎么用-程序员宅基地
- unity3dButton组件详细用法_unity button怎么用-程序员宅基地
- 安全***需要掌握的东西-程序员宅基地
- linux gs pdf,linux – 什么是汇编中的%gs-程序员宅基地
- 模拟退火算法matlab代码实现-程序员宅基地
- jQuery 语法实例_jquery-syntax示例-程序员宅基地
- Anaconda 安装与TensorFlow安装_error: pytest-astropy 0.8.0 requires pytest-cov>=2-程序员宅基地
- Assembly基础知识-程序员宅基地